bigfunctions > explore_column
explore_column¶
Signature
explore_column(fully_qualified_column)
Description
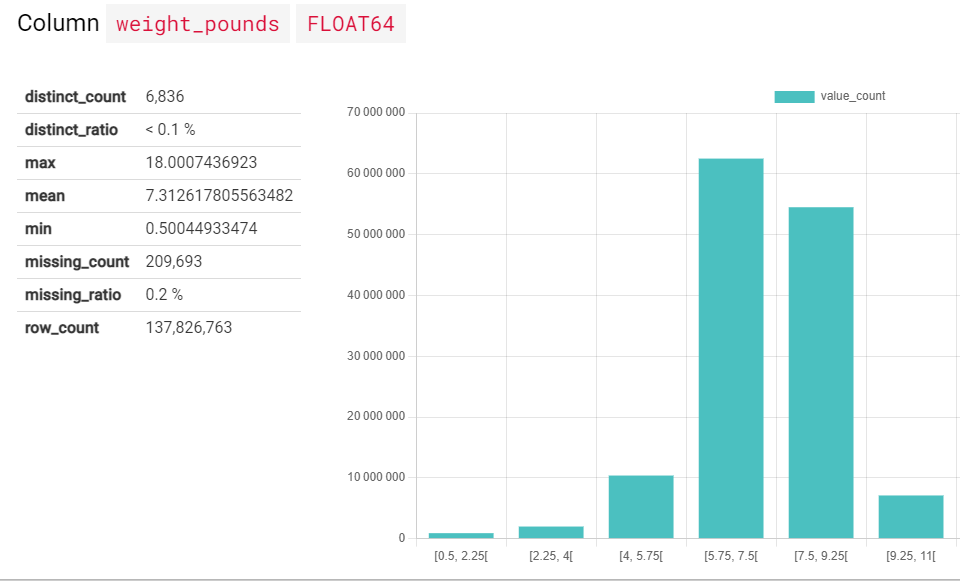
Show column statistics
See the result as a data visualization in BigQuery Console!
The result of this function can be vizualized as an html report directly in BigQuery Console!
- Install this bookmarklet: bigfunctions (it has to be done only once)
- Open BigQuery console
- Click on the installed bookmarklet.
- From now on, the bookmarklet code will observe the BigQuery console page.
- If a BigQuery result appears with a unique cell containing html content, it will be rendered.
- You will have to click on the bookmarklet again:
- If you refresh the Bigquery console page,
- If you open the BigQuery console in a new tab of your browser.
- Run the query of the example and open the result of the latest subquery. The result will be shown as a nice html content.
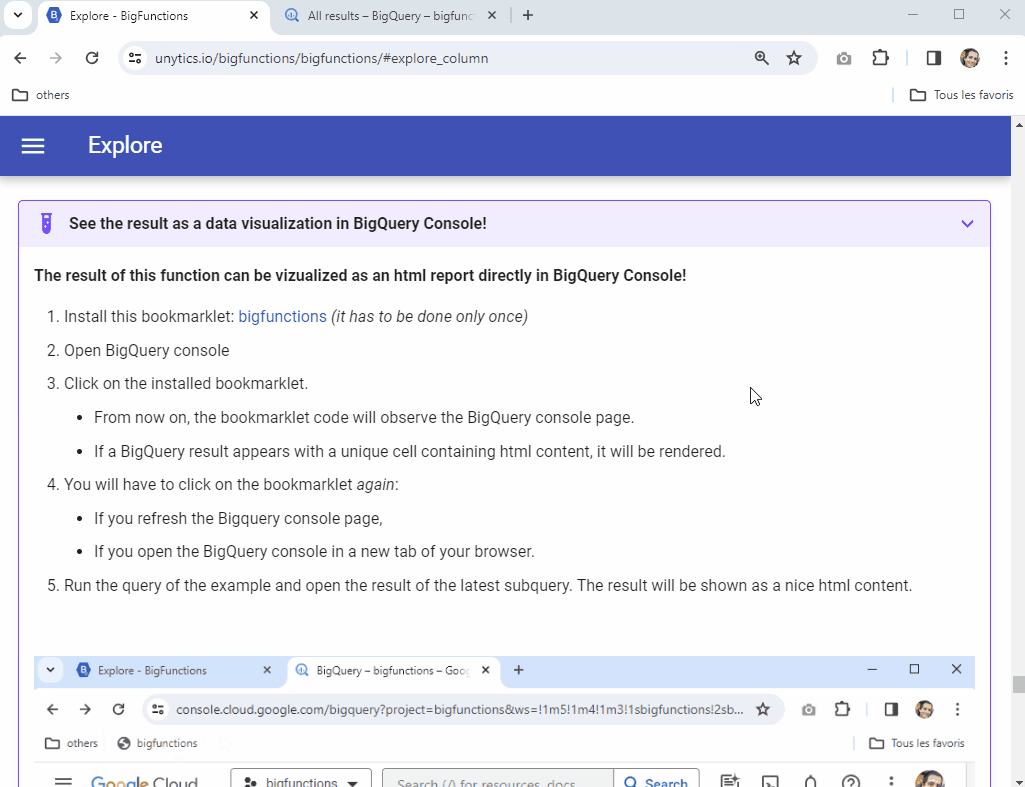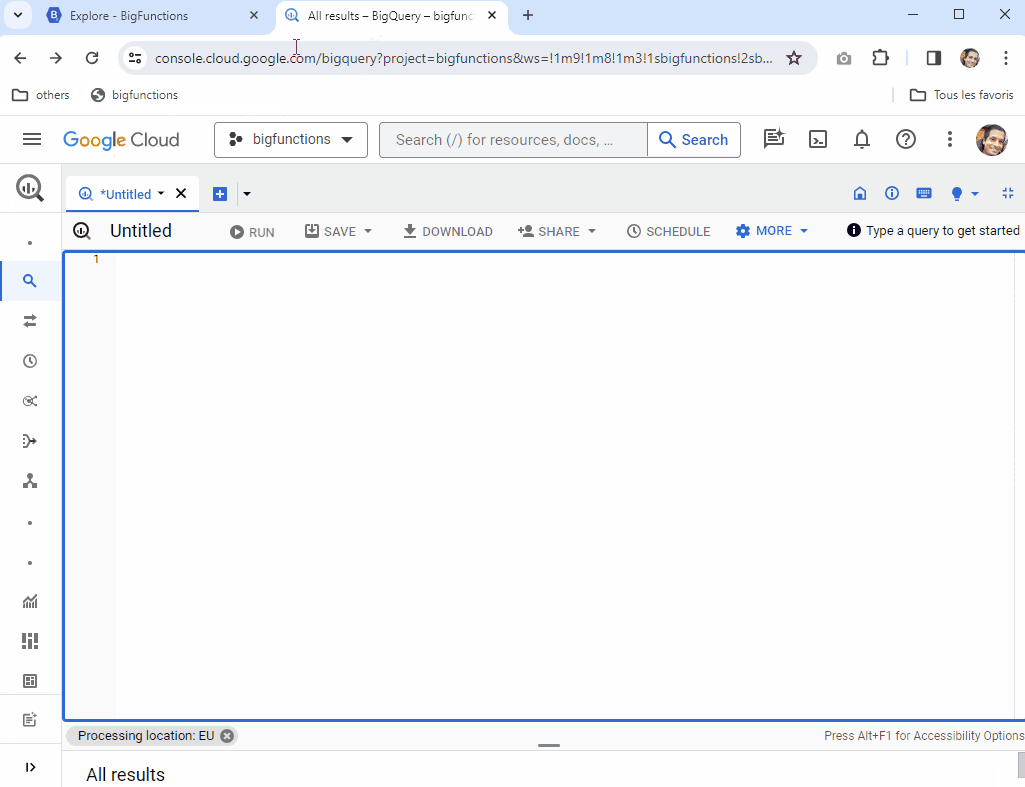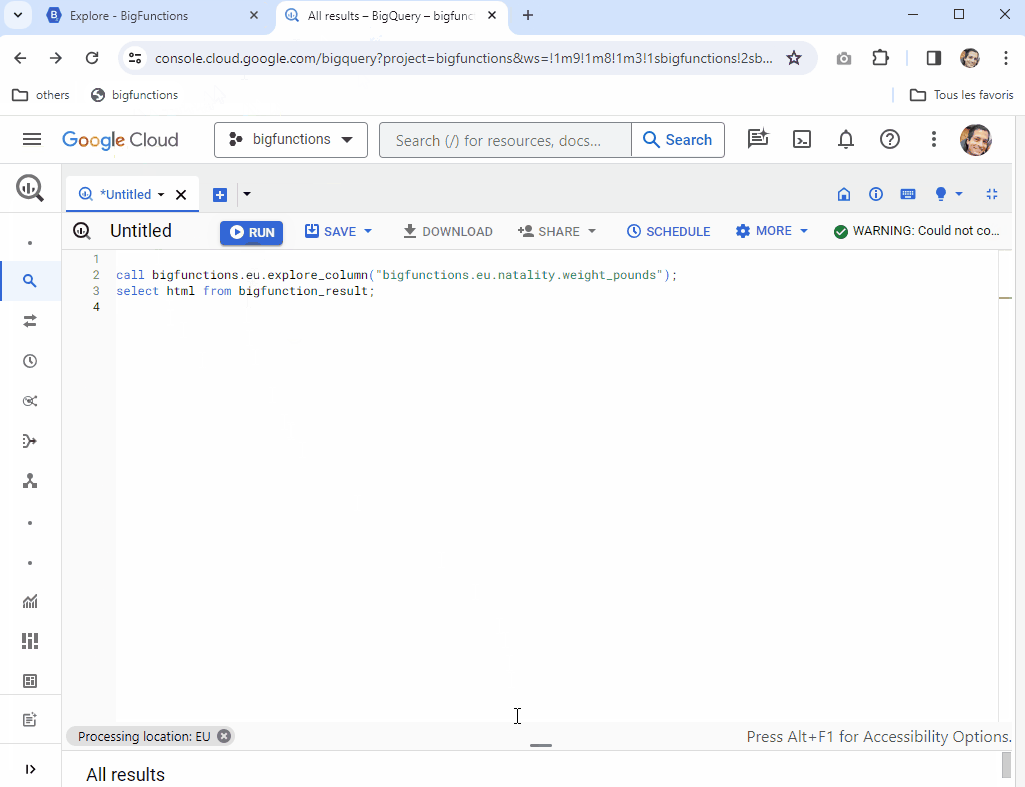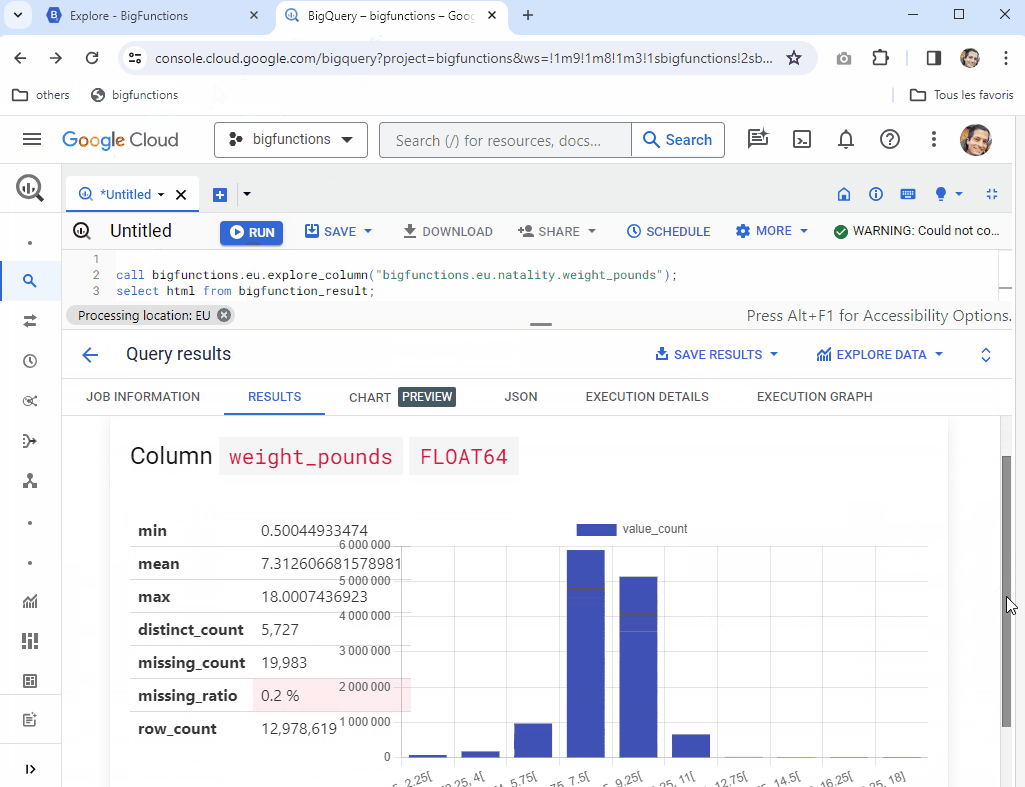
Examples
call bigfunctions.eu.explore_column("eu.natality.weight_pounds");
select html from bigfunction_result;
call bigfunctions.us.explore_column("us.natality.weight_pounds");
select html from bigfunction_result;
call bigfunctions.europe_west1.explore_column("europe_west1.natality.weight_pounds");
select html from bigfunction_result;